




2016年,特斯拉宣布其生产的所有特斯拉汽车(包括入门车型 Model 3)都将配备可实现完全自动驾驶功能的硬件,并且安全级别将远远高于人类自己驾驶。
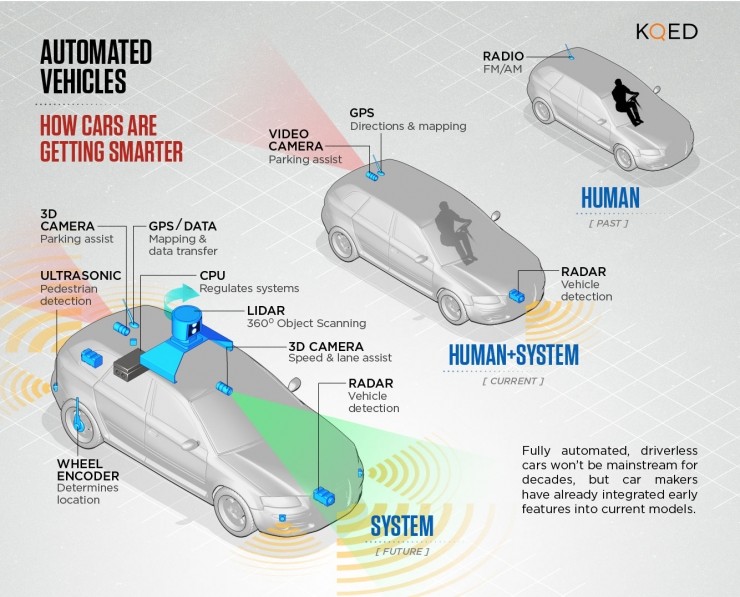
无人驾驶:以视觉为主还以激光雷达为主?

有意思的是,近日 Google 和特斯拉都公布了各自的测试里程数。
看到这条消息,让我想到了有关无人驾驶实现路径的两个主要问题:
信息输入端(Input):视觉还是激光雷达?
信息处理端(Processing):算法为王还是数据为王?
无人驾驶汽车上主要的传感器:激光雷达、摄像、毫米波雷达、GPS、超声波雷达和车轮转角传感器等。
无人驾驶:以视觉为主还以激光雷达为主?
Elon Musk 曾经在公开场合多次说过,不用激光雷达只用摄像头,也能实现 Level 4 以上的无人驾驶。但是我个人觉得他这么说其实是有商业化方面的考虑。
特斯拉的汽车已经在售,卖出去的车只能更新软件,肯定不能换硬件,比如全部重新装上激光雷达(不然今天特斯拉官方也不会说现在在产的特斯拉汽车会换上新的硬件系统)。
况且,Google 无人车用的 64 线 Velodyne 激光雷达本身的价格高达 75000 美元,这几乎和低配版特斯拉在美国的售价差不多了。
特斯拉的车要卖的好必须控制成本,Google 的无人车目前还只是处于测试阶段,几百辆的规模当然可以什么好用用什么,相比于特斯拉几万的产销量,花不了多少钱。
今年 5 月 7 日,美国佛罗里达州的一位特斯拉车主在使用 Autopilot 时发生车祸,最终不幸生亡。由此还导致给特斯拉提供计算机视觉技术的 Mobileye 创始人 Amnon Shashua 与 Elon Musk 之间的口水战,双方最终还闹掰了:Mobileye 宣布在与特斯拉合同结束后不再继续合作。
在特斯拉 9 月 11 日发布的Autopilot 8.0 版本中,特斯拉把毫米波雷达采集到的数据作为了控制系统判断的主要依据,而不是之前 Mobileye 的摄像头。
说起 5 月份的车祸,其实在车祸发生前,特斯拉的毫米波雷达已经感知到有障碍物,但是摄像头因光线的问题,没有发现在蓝天白云背景下的大货车,最后导致车祸发生。Musk 肯定也知道了摄像头并不靠谱,所以才在 Autopilot 的新版本中把毫米波雷达的数据作为主要参考依据。
综上所述,Musk 说「不用激光雷达只用摄像头,也能实现 Level 4 以上的无人驾驶」更多是出于商业化方面的考虑。
此举意在一边用现有的传感器收集数据,一边等激光雷达价格降下来。个人认为,如果固态激光雷达的价格真能如宣传中所说下降到 100 美元到 200 美元,为了保证汽车行驶的安全性,Musk 肯定是会用的。
大数据与算法:对于实现无人驾驶哪个更重要?
一年前这个时候,下图所示的微博引起了网友们的争论。
一方认为:数据为王,再牛的智能算法也拼不过海量的数据。而另一方则认为:数据只是建材,强大的分析能力才能让它变成摩天大楼,对效率的追求导致了算法,大数据取代不了算法。
有意思的是,近日 Google 和特斯拉都公布了各自的测试里程数。
据华尔街日报美国当地时间 10 月 5 日报道,Google 宣布自己的无人驾驶汽车刚刚完成 200 万英里道路行驶里程。而特斯拉创始人 Elon Musk 也于几天后在个人 Twitter 上宣布:特斯拉 Autopilot 发布后的 1 年中累计行驶里程已达到 2.22 亿英里。

Google 和特斯拉两方的表态表面上似乎也印证了微博讨论中双方的观点:数据为王 VS 算法为王。那实际情况究竟如何?
我们不妨考虑另一个类似的现象:大多数人认为 Google 的搜索比微软的 Bing 搜索在质量上做得略好一点的原因是 Google 的算法好。
但在前 Google 工程师吴军博士看来,「这种看法在 2010 年之前是对的,因为那时 Bing 在技术和工程方面明显落后于 Google。但今天这两家公司在技术上已经相差无几了,Google 还能稍稍占优,很大程度上靠的是数据的力量。」
与搜索算法尚不成熟的 2000 年不同,今天已经不存在一个未知的方法,仅凭它就能将准确率提高哪怕一个百分点。Google 凭借 PageRank 算法给搜索结果带来了质的变化,而好的搜索结果能吸引更多的用户使用 Google 的搜索引擎,这不知不觉间给 Google 提供了大量的点击数据。
有了这些数据之后,Google 可以训练出更精确的「点击模型」,而点击模型贡献了今天搜索排序至少 60% 到 80% 的权重,这将吸引更多的用户,整个过程是一个典型的不断自我强化的正反馈过程。
在 Google 内部,产品经理们都遵循这样一个规则:在没有数据之前,不要给出任何结论。由此可见,Google 的企业使命已经融入了员工的日常工作中。Google 正是充分利用了大数据的力量,顺利成为了对整张互联网举足轻重的枢纽节点,非常自然地实现了对互联网的垄断。
再举一个例子,9 月 27 日 Google 发布了新版本的神经机器翻译系统(Google Neural Machine Translation,GNMT),宣称该系统的翻译质量接近人工笔译。
大多数网友在实际测试过后,表示眼前一亮。与此同时,这也引起了某些翻译工作者的恐慌:「作为翻译看到这个新闻的时候,我理解了 18 世纪纺织工人看到蒸汽机时的忧虑与恐惧。」而这其实也是充分利用大数据的结果。
其实早在 2005 年,Google 的机器翻译质量就让全世界从事自然语言处理的人震惊不已了:从来没有从事过机器翻译的 Google,在美国国家标准技术研究所(National Institute of Standards and Technology,NIST)的年度测评中遥遥领先。
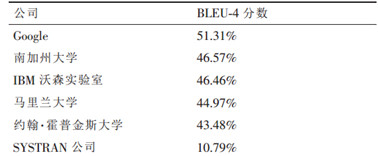
如下图所示,在阿拉伯语到英语翻译的封闭测试集中,Google 系统的 BLUE 评分为 51.31%,领先第二名将近 5%,而提高这 5 个百分点在过去需要研究 5 到 10 年。
Google 究竟是做到的呢?除了 Google 一贯的行事风格——把该领域全世界最好的专家、南加州大学 ISI 实验室的弗朗兹-奥科(Franz Och)博士挖过来之外,最关键的还是 Google 手里握有改进机器翻译系统所需要的大数据。
机器翻译专家 Franz Och,供职于人类长寿公司(后来他又转行到了大数据医疗领域)
从奥科 2004 年加入 Google 到 2005 年参加 NIST 测试,期间只有一年时间,如此短的时间只够他将在南加大的系统用 Google 的程序风格重新实现一遍,完全没有额外的时间做新的研究。而从上图中我们可以看到,Google 和南加大系统的水平差了 5 到 10 年。
其中的秘密就在于:奥科在 Google 还是用的在南加大使用过的方法,但充分利用了 Google 在数据收集和处理方面的优势,使用了比其他研究机构多上万倍的数据,训练出一个机器翻译的六元模型(一般来讲 N 元模型的 N 值不超过 3)。当奥科使用的数据是其他人的上万倍时,量变的积累导致了质变的发生,而这就是当今人工智能领域最权威的几位专家之一杰弗里-辛顿(Geoffrey Hinton)教授所坚持的「多则不同」吧。
值得一提的是,上图中的排在末位的 SYSTRAN 公司是一家使用语法规则进行翻译的企业,在科学家们还没有想到或者有条件利用统计的方法进行机器翻译之前,该企业在机器翻译领域是最领先的。但现在与那些采用了数据驱动的统计模型的翻译系统相比,它的翻译系统就显得非常落后了。
经过上述分析,对本小结的问题终于可以下一个较安全的结论:在当下的企业竞争中,相比于算法或数学模型,数据的重要性的确要大得多,即数据为王。
因为前者往往由学术界在几十年前就已经发现了,所有企业都可以加以利用,但是多维度的完备数据并不是每一个企业都拥有的。
今天很多企业在产品和服务的竞争,某种程度上已经是数据的竞争了,可以说没有数据就没有智能。因为从理论上讲,只要能够找到足够多的具有代表性的数据,就可以利用概率统计结果找到一个数学模型,使得它和真实情况非常接近,从而节省了大量人力成本或给予了用户更愉悦的体验。
总结
特斯拉已经积累的 2.22 亿英里行驶数据,以及未来将要积累的数据,对于他们研发 Level 4 以上的无人驾驶汽车是非常有帮助的,特斯拉可能会最终会先 Google 一步实现量产。
目前出于商业化的考虑,已量产的特斯拉用「摄像头 毫米波雷达 超声波雷达」作为主要传感器,但是等到低成本的固态激光雷达性能更稳妥。我相信 Musk 肯定是会装上去的(有网友已经在加州的道路上拍到头上顶着激光雷达的特斯拉汽车偷偷在做测试了),因为这对于保证实现 99.9999% 的车辆行驶安全性是非常有帮助的。
转载请注明出处。

 相关文章
相关文章
 热门资讯
热门资讯
 精彩导读
精彩导读






























 关注我们
关注我们

