





靠一个摄像头拍下的图像做3D目标检测,究竟有多难?目前最先进系统的成绩也不及用激光雷达做出来的1/10。
一份来自剑桥的研究,用单摄像头的数据做出了媲美激光雷达的成绩。
还有好事网友在Twitter上惊呼:
这个能不能解决特斯拉不用激光雷达的问题?马斯克你看见了没?

靠“直觉”判断
为何人单眼能做到3D识别,而相机却做不到?
因为直觉。
人能够根据远小近大的透视关系,得出物体的大小和相对位置关系。
而机器识别拍摄的2D照片,是3D图形在平面上的投影,已经失去了景深信息。
为了识别物体远近,无人车需要安装激光雷达,通过回波获得物体的距离信息。这一点是只能获得2D信息的摄像头难以做到的。
为了让摄像头也有3D世界的推理能力,这篇论文提出了一种“正投影特征转换”(OFT)算法。
作者把这种算法和端到端的深度学习架构结合起来,在KITTI 3D目标检测任务上实现了领先的成绩。

这套算法包括5个部分:
- 前端ResNet特征提取器,用于从输入图像中提取多尺度特征图。
- 正交特征变换,将每个尺度的基于图像的特征图变换为正投影鸟瞰图表示。
- 自上而下的网络,由一系列ResNet残余单元组成,以一种对图像中观察到的观察效果不变的方式处理鸟瞰图特征图。
- 一组输出头,为每个物体类和地平面上的每个位置生成置信分数、位置偏移、维度偏移和方向向量等数据。
- 非最大抑制和解码阶段,识别置信图中的峰值并生成离散边界框预测。
效果远超Mono3D
作者用自动驾驶数据集KITTI中3712张训练图像,3769张图像对训练后的神经网络进行检测。并使用裁剪、缩放和水平翻转等操作,来增加图像数据集的样本数量。
作者提出了根据KITTI 3D物体检测基准评估两个任务的方法:最终要求每个预测的3D边界框应与相应实际物体边框相交,在汽车情况下至少为70%,对于行人和骑自行车者应为50%。
与前人的Mono3D方法对比,OFT在鸟瞰图平均精确度、3D物体边界识别上各项测试成绩上均优于对手。

尤其在探测远处物体时要远超Mono3D,远处可识别出的汽车数量更多。甚至在严重遮挡、截断的情况下仍能正确识别出物体。在某些场景下甚至达到了3DOP系统的水平。

不仅在远距离上,正投影特征转换(OFT-Net)在对不同距离物体进行评估时都都优于Mono3D。
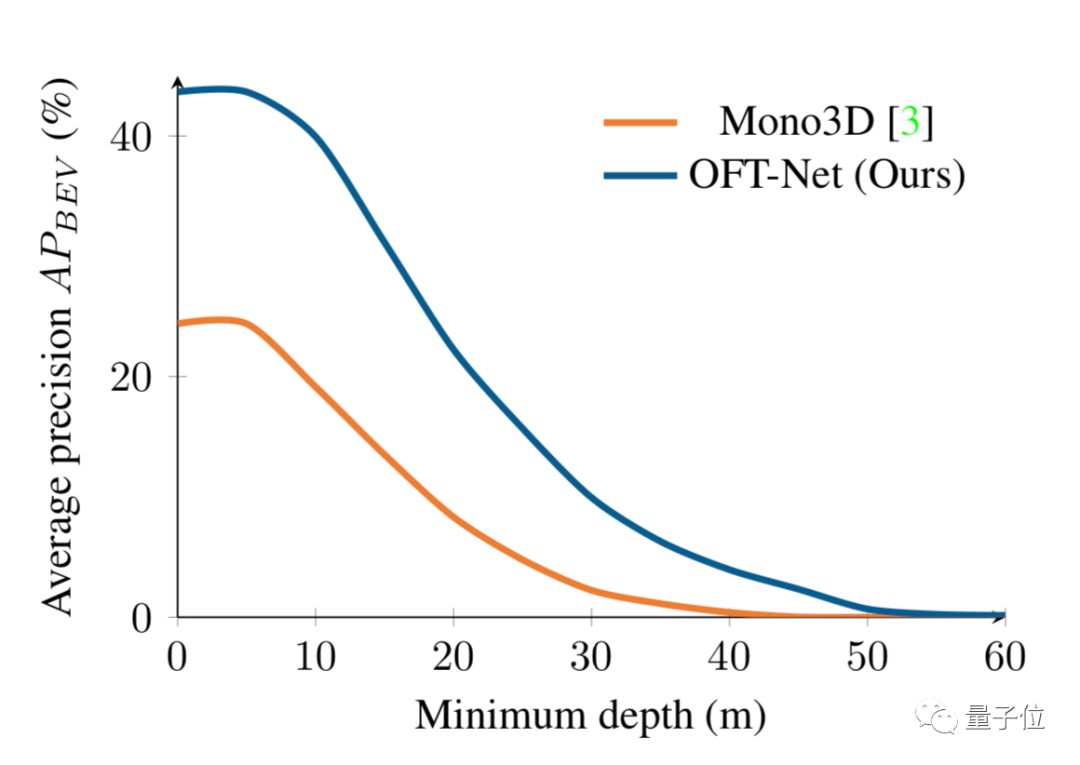
但是与Mono3D相比,这套系统性能也明显降低得更慢,作者认为是由于系统考虑远离相机的物体造成的。
在正交鸟瞰图空间中的推理显著提高了性能。为了验证这一说法,论文中还进行了一项研究:逐步从自上而下的网络中删除图层。
下图显示了两种不同体系结构的平均精度与参数总数的关系图。
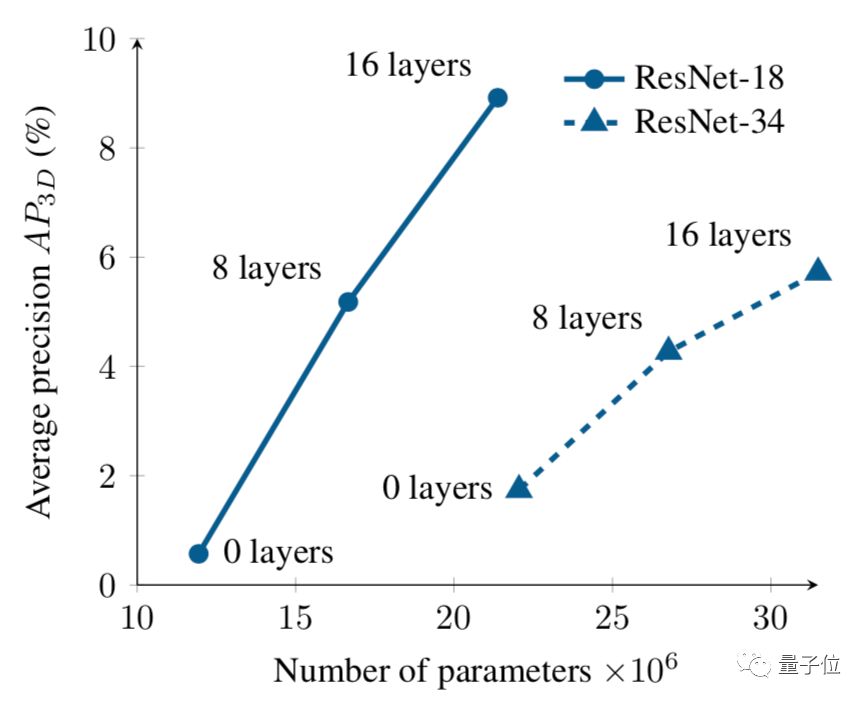
趋势很明显,在自上而下网络中删除图层会显着降低性能。
这种性能下降的一部分原因可能是,减少自上而下网络的规模会降低网络的整体深度,从而降低其代表性能力。
从图中可以看出,采用具有大型自上而下网络的浅前端(ResNet-18),可以实现比没有任何自上而下层的更深层网络(ResNet-34)更好的性能,尽管有两种架构具有大致相同数量的参数。
资源
论文:
Orthographic Feature Transform for Monocular 3D Object Detection
https://arxiv.org/abs/1811.08188
作者表示等论文正式发表后,就放出预训练模型和完整的源代码。
转载请注明出处。

 相关文章
相关文章
 热门资讯
热门资讯
 精彩导读
精彩导读
























 关注我们
关注我们

